- Hochschule Trier
- Campus wählen
- Quicklinks
-
- English
Im Folgenden werden die typischen Tätigkeiten während eines Projekts beschrieben. Deren Ausprägung und konkreter Ablauf hängt sehr stark vom verwendeten Vorgehensmodell ab, weshalb wir hier nur ganz allgemein in Phasen gliedern.
Zu Anfang eines jeden Projekts sollte man sich über die Ziele und Anforderungen im Klaren werden und diese im Detail aufschreiben.
Zu Anfang eines jeden Projekts sollte man sich über die Ziele und Anforderungen im Klaren werden und diese im Detail aufschreiben. Diesem Zweck dienen Dokumente wie das Lasten- und Pflichtenheft. Im Lastenheft wird zunächst das Problem im Detail und anschließend die Ziele des Projekts beschrieben. Daraus resultieren verschiedene Arten von Anforderungen, die zum Erreichen der Ziele notwendig sind. Das Lastenheft wird in Zusammenarbeit mit dem Kunden / Betreuer erstellt und dient als Basis für das Pflichtenheft. Im Pflichtenheft hingegen wird beschrieben, wie das Team gedenkt die Anforderungen technisch umzusetzen. Dazu gehört dann, je nach Projekt, unter anderem das Aufstellen eines Modells, die Definition von Schnittstellen sowie der Entwurf einer grafischen Benutzeroberfläche.
Wie ein solches Dokument aufgebaut sein kann, ist zum Beispiel in dem IEEE-Standard 830-1998 festgelegt[6].
An folgenden Qualitätsmerkmalen für Anforderungen kann man sich bei deren Formulierung orientieren:
Atomarität der Anforderungen
Anforderungen sollten atomar sein, d.h. nur genau eine Anforderung beschreiben, die sich nicht weiter in mehrere Anforderungen unterteilen lässt. Auf diese Weise wird es möglich, später genau sagen zu können, ob die Anforderung erfüllt ist oder nicht.
Eindeutigkeit der Anforderungen
Für jede formulierte Anforderung muss man sich die Frage stellen, wie viel Platz für mögliche Fehlinterpretationen übrig geblieben ist. Wichtig dabei ist, dass sich sowohl das Team als auch der Kunde über den Sinn und Zweck der Anforderung einig sind. Dabei sollte jedoch auch eine gewisse Zweckmäßigkeit beibehalten werden, da eine Formulierung schnell unnötig lang wird. Grundsätzlich gilt: So knapp wie möglich, so lang wie nötig.
Messbarkeit der Anforderungen
Eine Anforderung ergibt nur dann einen Sinn, wenn zu jeder Zeit festgestellt werden kann, ob diese bereits erfüllt ist oder nicht. Aus diesem Grund sollte eine Anforderung stets messbar sein. Das kann zum Beispiel dadurch erreicht werden, in dem konkrete Zahlenwerte für Grenzen existieren.
Realisierbarkeit der Anforderung
Eine Anforderung muss immer auch die Chance haben, realisiert werden zu können. Es ergibt keinen Sinn Anforderungen zu formulieren, bei denen von vorneherein klar ist, dass sie nicht umgesetzt werden können.
Vollständigkeit der Anforderungen insgesamt
Am Ende der Anforderungssammlung muss sich gefragt werden, ob tatsächlich alle geforderten Funktionen beschrieben und deren Rahmenbedingungen erfasst sind. Dies ist vor Beginn der Planungsphase ein wichtiges Ziel, da nachträglich hinzukommende Anforderungen möglicherweise schwer zu integrieren sind.
Ein häufiger Fehler ist, dass die gesammelten Anforderungen von ihrer Qualität her nicht ausreichend sind. So kann es zu Missverständnissen zwischen Kunden und Projekt-Team kommen. Um dies zu vermeiden sollte stets sichergestellt werden, dass mit dem Kunden Einigkeit darüber besteht, wie die einzelnen Anforderungen gemeint sind.
Nachdem möglichst alle Anforderungen erfasst und mit dem Kunden / Betreuer abgestimmt sind, beginnt die Entwurfsphase der Software. Teile davon fließen ebenfalls in das Pflichtenheft mit ein und sind somit Bestandteil des Vertrags mit dem Kunden / Beteuer. Welche Aspekte dazugehören, hängt stark von der Art und des Umfangs der zu entwickelnden Software ab. Wir werden im Folgenden einige typische Softwarekomponenten aufzählen und jeweils beschreiben, wie und mit welchem Werkzeug ein Entwurf möglich ist.
In den meisten Softwareprojekten spielt die Grafische Benutzeroberfläche (kurz GBO oder GUI) eine entscheidende Rolle dabei, ob die Software von den Nutzern und damit vom Kunden akzeptiert wird, oder nicht. Oft gibt es für die Bedienung bzw. für die Erfassung von Daten mehrere unterschiedliche Möglichkeiten der Realisierung und oft ist die erste Idee nicht unbedingt die beste. Grundsätzlich sollte von Nutzerseite an dieses Problem heran gegangen werden, d.h. es sollte herausgefunden werden, welche Aktionen und Ziele der Benutzer während der Nutzung der Software wann und wie oft verfolgt. Daraus ergeben sich wichtige Informationen darüber, welche Bedienelemente beispielsweise besonders häufig genutzt werden und somit, wie viel Energie in eine effiziente Bedienbarkeit gesteckt werden sollte. Die gesammelten Anforderungen geben bereits Hinweise darauf und können durch weitere Nutzerbefragungen ergänzt werden. Ergebnis können sogenannte Usecase-Diagramme sein und darauf aufbauend erste GUI-Entwürfe.
Usecase-Diagramme sind Teil der UML-Spezifikation und somit von den meisten UML-Tools unterstützt. Ein freies und sehr mächtiges UML-Tool ist Astah-Community[7].
Für einen ersten GUI-Entwurf eignet sich, neben vielen speziellen Tools, besonders eine Präsentationssoftware wie Microsoft Powerpoint oder OpenOffice Impress. Die Idee ist dabei auf einzelnen Folien die Zustände der Bedienelemente abzubilden und diese dann geschickt miteinander zu verlinken.
Beispiel: Angenommen, man würde die Auswahl aus einem Dropdown-Feld simulieren wollen. Dann gäbe es eine Folie, bei der das Feld eingeklappt (1), eine weitere wo diese aufgeklappt ist (2) und schließlich eine, wo ein Eintrag erfolgreich ausgewählt wurde (3). Zu (2) kommt man, indem auf den Pfeil neben der Dropbox geklickt wird. Zu (3) dann durch Klicken auf die Liste.
Auf diese Weise kann bereits sehr früh ein GUI-Entwurf präsentiert werden, der sogar ein Gefühl darüber vermittelt, wie die Bedienung später aussieht. Die Nutzer können früh ihr Feedback abgeben und es wird sehr viel Zeit damit gespart, dass der Ablauf der Bedienung schon vor der eigentlichen Implementierung klar ist.
Sollte es für die gegebene Problemstellung erforderlich sein, dass ein neuer Algorithmus erstellt werden muss, so empfiehlt sich der Entwurf zunächst in Pseudo-Code. Dies hat die folgenden Vorteile:
Hier werden alle Überlegungen getroffen, die den Zugriff und die Verwaltung der zu verarbeitenden Daten betrifft. Sollen die Daten in einer Datenbank gespeichert werden, eignet sich zum Entwurf ein ER-Diagramm[8]. Darin ist festgehalten, welche Entitäten existieren und wie die Beziehungen untereinander aussehen. Eine weitere Überlegung könnte sein, ob ein sogenannter OR-Mapper[9] verwendet werden soll. Auf diese Weise erspart man sich das manuelle Mapping der Datenbank auf geeignete Datenstrukturen der Programmiersprache. Ein bekannter OR-Mapper für Java ist beispielsweise Hibernate[10].
Egal für welche Persistierungs-Methode man sich entscheidet oder ob überhaupt eine Persistierung stattfindet, die zu verarbeitenden Daten müssen in jedem Fall irgendwie repräsentiert sein. Im Allgemeinen sind dabei folgende Gesichtspunkte zu berücksichtigen:
Hier gilt es zu analysieren, wie die Anwendung sinnvoll in Komponenten aufgeteilt werden kann und wie diese voneinander abhängen. Je nach Anwendungstyp hat das unterschiedliche Auswirkungen auf den Entwurf. Im Allgemeinen möchte man einzelne Komponenten, die unabhängig voneinander entwickelt und getestet werden können und über vordefinierte Schnittstellen kommunizieren. Dies ermöglicht erst die zeitgleiche Entwicklung der Anwendung mit mehreren Teammitgliedern.
Es gibt verschiedene Lösungsansätze und Entwurfsmuster, wie eine saubere und sinnvolle Unterteilung in Komponenten umgesetzt werden kann. Diese sind meist sprachunabhängig, da die verwendeten Eigenschaften von den meisten gängigen (objektorientierten) Programmiersprachen unterstützt werden. Einige werden wir im Folgenden vorstellen, die sich im Zusammenspiel als sehr geeignet erwiesen haben. Dazu zählen die folgenden:
Unterteilt man eine Anwendung in Komponenten, so gibt es oft eine, die von mehreren anderen verwendet wird.
Eine naive Herangehensweise wäre ganz zu Anfang ein Objekt dieser Komponenten zu erzeugen und die Referenz über Konstruktoren "durchzureichen". Der Nachteil ist, dass bei einer hierarchischen Struktur der Komponenten auf diese Weise die Anzahl der Konstruktoren-Parameter anwächst. Zudem gibt es den Fall, dass eine Komponente A, die von C verwendet wird, erst über B gereicht werden muss, da C erst von B erzeugt wird. B selbst braucht die Komponente jedoch nicht. So entstehen Abhängigkeiten zwischen Komponenten, die nicht notwendig sind.
Statische Attribute und Methoden einer Klassen lösen das Problem insofern, als dass diese von überall aus per qualifiziertem Aufruf erreichbar sind. So müssen keine Objekte durch Konstruktoren durchgereicht werden und es bleibt bei einer flachen Abhängigkeitshierarchie. Nachteil ist, dass hier die Vorteile der Vererbung auf der Strecke bleiben.
Das Entwurfsmuster Singleton verbindet nun die Vorteile aus den zuvor besprochenen Ansätzen. Das eine Objekt der Klasse wird dabei in einem privaten, statischen Attribut innerhalb der Klasse selbst gespeichert (z.B. instance). Andere Komponenten beschaffen sich die Referenz auf dieses Objekt mittels einer statischen, öffentlichen Methode (z.B. getInstance). Die Erzeugung der Instanz erfolgt beim ersten Methodenaufruf. Die Klasse hat nur private Konstruktoren, was die Erzeugung zusätzlicher Instanzen von außerhalb verhindert.
Weitere Informationen zu dem Entwurfsmuster Singleton sind in dem Wikipedia-Artikel zu finden[11]. Eine weitere Lösung für das Problem ist die sogenannte Dependency Injection[12]. Für Java existiert beispielsweise das von Google entwickelte Framework Google Guice[13], was den "Injektionsvorgang" mit Hilfe von Java Annotations[14] besonders komfortabel macht.
Wenn eine Instanz eines Objekts benötigt wird, erzeugt man das neue Objekt normalerweise mit Hilfe des Schlüsselwortes new (in Java). Der passende Konstruktor wird aufgerufen und eine Referenz auf das Objekt zurück geliefert. Nun kann es jedoch vorkommen, dass man besondere "Ausführungen" eines Objekts haben möchte. Instanzen, bei denen bestimmte Attribute bereits mit bestimmten Werten vorbelegt sind, ohne dass jedoch andere Informationen beim Erzeugen gebraucht und somit ein anderer Konstruktor benötigt werden würde.
Dieses Problem löst das Entwurfsmuster Factory, wobei es auch hier verschiedene Varianten gibt. Die einfachste sieht so aus, dass der Konstruktor einer Klasse als private deklariert wird und stattdessen beliebig viele statische Erzeuger-Methoden existieren, die unterschiedliche Varianten eines Objekts erzeugen und dessen Referenz zurück liefern.
Weitere Informationen zu den Entwurfsmuster Factory sind zum Beispiel auf Wikipedia zu finden[15].

MVC ist ein Entwurfsmuster zur Strukturierung einer Software mit dem Ziel, später notwendig werdende Änderungen oder Erweiterungen zu vereinfachen und einzelne Teile wiederverwendbar werden zu lassen. Es setzt sich zusammen aus einem sogenannten Model (Datenhaltung und je nach Variante auch Geschäftslogik), einem Controller (Entgegennahme und Auswertung der Benutzereingaben) sowie einer View(Präsentation der Daten). Das Konzept sieht vor, dass der Controller Datenänderungsanfragen an das Modell weitergibt, dieses wiederum nimmt seinerseits die Änderung vor und benachrichtigt alle Views, die sich für eine Datenänderung des Models interessieren. Dazu können sich beliebig viele Views an dem Modell als Listener anmelden.
Auf diese Weise wird eine Trennung und Austauschbarkeit von Datenhaltung, Anzeige und Geschäftslogik möglich. Außerdem skaliert das Konzept gut, da es dem Modell beispielsweise egal sein kann, wie viele unterschiedliche Views sich für Modell-Änderungen interessieren. Des Weiteren spielt es auch keine Rolle, auf welch unterschiedliche Arten der Benutzer Aktionen auslösen kann, die eine Datenänderung herbei führen, da das Model durch seine Methoden klar definierte Möglichkeiten bereitstellt, die von allen Controllern genutzt werden müssen.
Weitere Informationen zu MVC finden sich auf Wikipedia[16].

MVP unterscheidet sich vom klassischen MVC (Modell, View, Controller) in der Art und Weise, wie die drei Komponenten miteinander kommunizieren und wie die Verantwortlichkeiten verteilt sind. Während bei MVC die View das Modell kennt und von diesem über Änderungen benachrichtigt wird, kennt in MVP die zugehörige View das Modell nicht. Stattdessen übernimmt der Presenter die Kommunikation mit dem Modell und reicht die Änderungen an die View weiter. Auf diese Weise kann die gesamte Logik in den Presenter wandern, während die View ausschließlich alle Anzeige- und Steuerelemente enthält.
Auch hier gibt es verschiedene Varianten des Entwurfsmusters MVP. Die hier vorgestellte lehnt sich an die von Martin Fowler[17] definierte Variante mit dem Namen "Passive View" an. Das Entwurfsmuster lässt sich am einfachsten mit einem Beispiel erläutern.

Angenommen, es soll eine Anwendung geschrieben werden, mit Hilfe der Personen verwaltet werden können. Betrachten wir den Dialog, bei dem ein neuer Benutzer hinzugefügt werden kann (s. Abbildung rechts). Nachdem die Personendaten korrekt eingegeben wurden, kann der Benutzer auf OK klicken, um den Eintrag zu übernehmen, oder auf Abbrechen, um den Vorgang zu beenden. Außerdem wird das Feld Email auf syntaktische Korrektheit überprüft und alle Felder dürfen nicht leer sein. Das Ergebnis der Feldprüfung wird jeweils dahinter mit Hilfe eines Icons angezeigt. Außerdem soll der Button OK nur gedrückt werden können, wenn alle Eingaben korrekt sind.
Es gibt hier also verschiedene Interaktionen mit dem Benutzer, die wir im Folgenden kurz aufzählen.
Zunächst die Aktionsmöglichkeiten des Benutzers:
Die möglichen Aktionen der GUI:
Das Entwurfsmuster MVP ist nun so aufgebaut, dass sich View und Presenter jeweils kennen. Die View enthält ausschließlich die GUI-Komponenten, während der Presenter die zugehörige Logik enthält. Welche Methoden zur Kommunikation zur Verfügung gestellt werden müssen, wird durch zwei Interfaces festgelegt und kann aus den gesammelten Aktionen von Benutzer und GUI abgeleitet werden (s. oben).
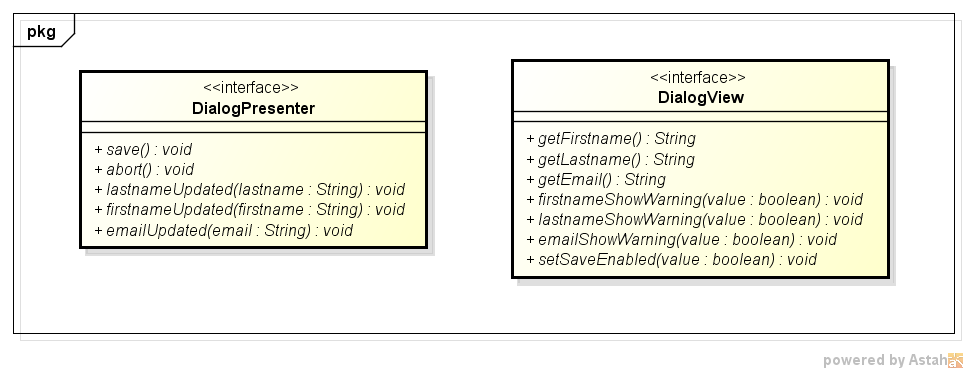
Jedes Mal wenn der Benutzer in der GUI nun den Inhalt der Eingabe-Felder ändert, wird der Presenter von der View mit Hilfe der entsprechenden Methoden informiert. Der Presenter überprüft daraufhin den Feldinhalt und veranlasst gegebenenfalls die View dazu, hinter den Feldern das Fehler-Icon dazustellen. Wenn mindestens eine Eingabe nicht korrekt ist wird außerdem die View dazu veranlasst, den OK-Button zu deaktivieren. Wichtig ist hier zu erkennen, dass die Namen der View-Methoden nicht vorschreiben, auf welche Art und Weise der Benutzer darüber informiert wird, was gerade falsch ist bzw. welche Aktionen er ausführen kann und welche nicht. Die Methoden sind semantisch benannt und lassen dem GUI-Entwickler die volle Kontrolle darüber, wie die Oberfläche aus Usability-Sicht aufgebaut ist. Die Methode setSaveEnabled(...) sagt beispielsweise nur, ob die Aktion "Speichern" vom Benutzer gerade ausgeführt werden kann oder nicht. Die View könnte anstatt den Button zu deaktivieren, diesen auch ganz verschwinden lassen, sollte das aus Gründen der Benutzbarkeit als sinnvoll angesehen werden.
In der anderen Richtung verhält es sich genauso. Der Presenter stellt zum Beispiel die Methode abort() zur Verfügung, die den Vorgang beendet. Es wird hier nicht vorgeschrieben, welche Möglichkeiten der Benutzer hat, diese Aktion auszuführen. Neben den Buttons Abbrechen und dem "X" oben rechts, könnte später vielleicht noch die "Esc-Taste" als dritte Möglichkeit hinzukommen. In allen drei Fällen wird auf dem Presenter die selbe Methode aufgerufen.
Auf diese Weise wird eine sehr natürliche Art der Trennung möglich. Die Wahl der notwendigen Interface-Methoden ergibt sich relativ intuitiv aus der Analyse der Benutzer-Interaktionen.
Ein weiterer großer Vorteil des Entwurfsmusters ist die äußerst gute Testbarkeit des Presenters mit Hilfe von Unit-Tests, da die View selbst keine nennenswerte Logik enthält. Dazu werden typischerweise sogenannte "View-Teststubs" erstellt, die das View-Interface implementieren, jedoch keine wirklichen GUI-Elemente erzeugen. Diese stellen zusätzlich Methoden zur Verfügung, die den Zustand des Teststubs für die Testklassen komfortabel setzen und auslesen lassen.
Ein Presenter-Test sieht im Allgemeinen wie folgt aus:
Trotz der oben genannten Vorteile sollte man sich stets über den Mehraufwand durch die zusätzlichen Interfaces im Klaren sein. MVP kann seine vollen Stärken besonders bei GUI-Komponenten mit ausgeprägter Benutzerinteraktion entfalten. Kleinere Views, die dem Benutzer ausschließlich etwas anzeigen, ohne dass dieser selbst mit ihr interagiert, brauchen keinen gesonderten Presenter. Hier reicht das klassische Observer-Muster, bestenfalls umgesetzt mit einem Eventbus (s. nächster Abschnitt).

Wir haben oben den Unterschied zwischen MVC und MVP kennen gelernt. MVC arbeitet zur Benachrichtigung der View typischerweise mit dem sogenannten Observer-Entwurfsmuster. Dabei hat ein Observer (zum Beispiel die View) die Möglichkeit, sich an einem Objekt (zum Beispiel dem Modell) als Listener anzumelden, um fortan über entsprechende Änderungen informiert zu werden. Dazu implementiert der Observer ein Interface, was von der zu überwachenden Entität zur Verfügung gestellt wird. Diese Entität ist außerdem für die Verwaltung der angemeldeten Observer-Objekte verantwortlich. Es muss Methoden zur Registrierung und Deregistrierung zur Verfügung stellen.
Das Problem hier ist, dass die Listener-Verwaltung in jeder überwachbaren Entität implementiert werden muss. Gibt es zudem unterschiedliche Ereignisse, erhöht sich der Implementierungsaufwand noch weiter, da für jeden Ereignis-Typ weitere Verwaltungs-Methoden hinzu kommen. Dieser Aufwand lässt sich reduzieren, wenn es nur einen Listener-Typ gibt und das Ereignis mit Hilfe von Enums unterschieden wird. Hier verlagert sich der Aufwand dann zum Observer, der sich möglicherweise nicht für alle Ereignistypen interessiert und anhand der Enums eine Fallunterscheidung durchführen muss.
An diesem Punkt setzt das Entwurfsmuster Eventbus an. Auch mit diesem kann man das Entwurfsmuster Observer umsetzen. Im Wesentlichen stellt ein Eventbus eine zentrale Ereignis-Quelle zur Verfügung, an denen sich Observer für Ereignisse anmelden können und bei entsprechendem Auftreten informiert werden. Gleichzeitig dient es Komponenten als zentrale Stelle, über die Ereignisse publik gemacht werden. Typischerweise existiert in einer Applikation nur genau ein Eventbus, der von allen Komponenten verwendet wird. So bietet es sich an, den Zugriff als Singelton zu implementieren. Daraus resultiert eine erhebliche Reduzierung des Implementierungsaufwands, da nicht mehr für jedes Modell eine Listener-Verwaltung geschrieben werden muss, was auch die Fehleranfälligkeit reduziert.
Ein weiterer wichtiger Vorteil ist die dadurch entstehende Entkopplung der Komponenten. Da der Eventbus nun als zentrale Einheit in die Mitte rückt, muss weder der Observer die tatsächliche Quelle des Ereignisses kennen, noch muss die Ereignisquelle wissen, wer tatsächlich auf das Ereignis reagiert. Ein Austausch bzw. die Erweiterung von zusätzlichen Quellen und Empfängern ist ohne Probleme möglich. Eine nützliche Erweiterung des Eventbus sieht außerdem die Einführung von sogenannten Topicsoder Channels vor. So kann eine Quelle Ereignisse nur über ein bestimmtes Topic veröffentlichen und ein Empfänger nur auf solche Ereignisse reagieren, die zu einem bestimmten Topic veröffentlicht wurden.
Auch hinsichtlich Testbarkeit bietet ein Eventbus besondere Vorteile. Zum Testen der Quelle muss sich der Unit-Test lediglich am Eventbus für das entsprechende Ereignis anmelden und darauf reagieren. Zum Testen eines Empfängers kann der Unit-Test als Ereignisquelle dienen.
Grundsätzlich sollte man die Wahl des Entwurfsmusters von Fall zu Fall ganz individuell treffen. Es ist nicht sinnvoll für alles zwanghaft ein einziges Muster zu verwenden, nur weil es das vermeintliche Gefühl von Konsistenz oder schöner Software-Architektur vermittelt. Außerdem sollte man sich überlegen, wann die Verwendung von Interfaces sinnvoll ist. Wenn zunächst nur eine Implementierung vorgesehen ist und eine weitere nur in der Theorie und in ferner Zukunft besteht, sollte man zunächst darauf verzichten und die Klasse ohne Interface implementieren. Auf diese Weise ändert sich nur an einer Stelle etwas, sollten während der Entwicklung noch einmal die Methoden-Signaturen geändert werden oder weitere Methoden hinzu kommen.
Der objektorientierte Softwareentwurf kann gut mit Hilfe von UML-Klassendiagrammen durchgeführt werden. Hier gilt wie bei allen Diagrammen: Nur so viele Details mit aufnehmen, wie es für den aktuellen Fall sinnvoll ist. Eine riesige Tapete aller Klassen mit Methoden und Attributen sowie jeglicher Beziehungen bringt selten die gewünschte Übersicht. Es ist sinnvoller lieber mehrere Diagramme für unterschiedliche Teile der Software zu haben, die jeweils auf ein anderes Detail eingehen. Es kann beispielsweise ein Diagramm geben, in dem die Hauptkomponenten als Klassen auftauchen und auch deren Beziehungen untereinander, nicht aber deren Methoden und Attribute. Vermutlich hilft es dem Leser auch nichts, alle Getter- und Setter in ein solches Diagramm mit aufzunehmen.
Bei der personellen Aufteilung der Implementierungsaufgaben gibt es nun verschiedene Varianten, die jeweils ihre Vor- und Nachteile haben.
Eine horizontale Aufteilung sähe vor, dass die Verantwortlichkeiten entlang der Software-Schichten geteilt werden. So wäre beispielsweise ein Teil des Teams für die Grafische Benutzeroberfläche zuständig, während sich ein weiterer Teil des Teams um die Geschäftslogik und die Datenhaltung kümmert. Ein letzter Teil könnte ausschließlich für die Implementierung der Algorithmen zuständig sein. Diese Aufteilung hat den Vorteil, dass die einzelnen Teammitglieder jeweils ihr Spezialgebiet haben, in dem sie sich gut auskennen müssen und auf das sie sich voll und ganz konzentrieren können. Nachteil ist, dass gerade kleine Teams dadurch nicht sonderlich robust sind. Fällt ein Teammitglied im Laufe des Projekts aus, kann es im Team schnell an fachlicher Kompetenz mangeln, was zu größeren Verzögerungen führen kann.
Eine vertikale Aufteilung hingegen sieht vor, dass die Aufgabenverteilung eher Feature orientiert vorgenommen wird. Ein Teammitglied ist dabei voll für ein Feature verantwortlich und implementiert dieses über alle Software-Schichten hinweg. Auf diese Weise kann der Ausfall eines Teammitglieds besser kompensiert werden, da das gesamte Team von vorne herein in allen Schichten der Software eingewiesen ist. Nachteil ist hingegen, dass jeder Kompetenz in jedem Bereich besitzen muss, was ggf. anfangs zu höheren Einarbeitungszeiten führen kann.
Welche Aufteilung man für das Projekt wählt, sollte zu Anfang im Team besprochen werden. In die Entscheidung mit einfließen sollte dabei die Größe des Teams und auch die Vorkenntnisse der einzelnen Teammitglieder. Mischformen sind natürlich auch möglich. Wichtig ist nur, dass man sich gemeinsam Gedanken darüber macht, sich über die Konsequenzen klar wird und dann eine für das Projekt sinnvolle Vorgehensweise wählt.
Grundsätzlich ist es eine gute Idee sich vor der ersten Zeile Programmcode zu überlegen, was genau zu tun ist. Manchmal hilft es auch zunächst die Schritte in Form von Kommentaren untereinander zu schreiben und diese dann Schritt für Schritt abzuarbeiten.
Es gibt einige Fragen, die man sich während der Programmierung immer wieder stellen sollte:
Gelegentlich gibt es Nachbedingungen am Ende einer Methode, die dringend eingehalten sein müssen. Während der Entwicklung hilft es, diese in jedem Fall abzuprüfen und im Falle einer Verletzung eine Ausnahme zu werfen. Sollte es beim manuellen Testen des Programms eine Eingabe geben, die genau zu diesem Fall führt und möglicherweise bei den automatischen Tests vergessen wurde, wird man mit der geworfenen Ausnahme darauf hingewiesen. Viele Programmiersprachen bieten zu diesem Zweck sogenannte "Asserts" als Teil ihres Sprachumfangs.
Hier stellt sich oft die Frage: Was sollte man in Form von Kommentaren dazu schreiben und was ist bereits offensichtlich und somit beim Lesen und Verstehen hinderlich? Aus der Erfahrung lassen sich einige Fälle aufzählen, wann man in jedem Fall kommentieren sollte:
Außerdem sollten mindestens jene Public-Methoden dokumentiert werden, die von anderen Teammitgliedern verwendet werden sollen. Aus diesen Spezifikationen muss hervorgehen, was die Methoden im Allgemeinen machen, welche Eingabeparameter (inkl. Definitionsbereich) diese erwarten, was wann zurück gegeben wird (inkl. Wertebereich) und in welchen Fällen Exceptions geworfen werden. Viele Entwicklungsumgebungen bieten bei der Verwendung von Methoden einer fremden Klasse Hilfe in Form von Auto-Vervollständigungen und komfortabler Anzeige der Spezifikation an. Auf diese Weise muss das betroffene Teammitglied nicht selbst in den Quellcode der fremden Klasse schauen sondern kann sich voll und ganz auf die angezeigte Spezifikation verlassen. Daraus folgt natürlich, dass die Spezifikation stets aktuell gehalten sein muss. Inbesondere nachträgliche Änderungen müssen im Team kommuniziert werden.
Auch der Kopf einer Klasse sollte dokumentiert werden. Dabei ist eine kurze Beschreibung des Zwecks sinnvoll sowie mindestens ein hauptverantwortlicher Autor.
Wenn man im Rahmen des Projekts für den Quellcode ein Versionierungstool wie Git oder SVN verwendet, was nur dringend empfohlen werden kann, stellt sich die Frage, wann und wie häufig die Arbeit versioniert werden sollte. Das hängt unter anderem davon ab, auf welchen Workflow man sich in dieser Hinsicht geeinigt hat. Folgende Situationen sind gute Zeitpunkte für einen Commit:
Diese ehere kleinen und atomaren Versionierungen haben auch den Vorteil, dass die anderen Teammitglieder mit Hilfe der Commit-Nachrichten gut nachvollziehen können, was im Einzelnen getan wurde.
Wie oben bereits angesprochen testet der Entwickler sein entwickeltes Feature vor der Versionierung regelmäßig und ausführlich selbst, bevor es zum weiteren Test an Teamkollegen weitergegeben wird. Erfahrungsgemäß passiert das weitestgehend manuell, indem das Programm gestartet und einige Eingaben geprüft werden. Hier ist es eine gute Idee stattdessen gleich erste Unit-Testfälle (beispielsweise mit JUnit[18]) zu schreiben. Dies ersetzt nicht das ausführliche Testen des Features (bestenfalls) durch eine weitere Person, hat aber den Vorteil, dass die geschriebenen Tests auf Knopfdruck immer wieder ausgeführt werden können.
Für viele Programmiersprachen stehen Test-Frameworks zur Verfügung, die das Schreiben von automatischen Tests recht einfach machen.
Um eine gute Lesbarkeit und Wartbarkeit des Quellcodes zu gewährleisten ist es wichtig, dass genaue Code-Conventionen festgelegt und durchgesetzt werden. Diese sollten am Anfang des Projekts vom Team bestimmt werden. Viele Entwicklungsumgebungen wie Eclipse unterstützen den Programmierer in dieser Hinsicht von Haus aus sehr gut. Code-Conventionen lassen sich über die Projekt-Einstellungen konfigurieren und der Quelltext wird beim Speichern durch sogenannte Save-Actions ggf. automatisch anhand dieser formatiert.
Hier ist man nun an einer Stelle im Projektverlauf angekommen, wo der Kunde / Betreuer die (möglicherweise erste) lauffähige Version der Software erhält. Das Produkt ist ausgiebig getestet und bereit nun endlich genutzt zu werden.
Vor der Auslieferung sollten allerdings einige organisatorische Schritte durchgeführt werden, die folgende Aktivitäten vereinfachen. Das gilt insbesondere dann, wenn die Software nach der Auslieferung noch weiter entwickelt wird.
Ein wichtiger Punkt ist die Versionierung. Die ausgelieferte Version sollte in der Versionsverwaltung entsprechend markiert (getagged) werden und als eigenständiger Branch existieren. Das hat den Vorteil, dass später hinzukommende Bug-Fixes für die ausgelieferte Version und die Entwicklung neuer Features klar getrennt und unabhängig voneinander geführt werden können. Auf diese Weise können neue Features implementiert werden, ohne dass diese beim nächsten Patch für den Kunden zwangsläufig mit ausgeliefert werden müssen.
Es ist eine gute Idee für den Auslieferungsprozess eine Check-Liste zu führen, um keine Punkte zu vergessen, z.B.:
Sie verlassen die offizielle Website der Hochschule Trier