- Hochschule Trier
- Campus wählen
- Quicklinks
-
- English
Die Qualitätssicherung während eines Software-Projekts begrenzt sich nicht ausschließlich auf die Tests während und nach der Implementierung. Vielmehr sollten in allen Projektphasen kontinuierlich qualitätssicherende Maßnahmen eingeplant und durchgeführt werden. Das betrifft sowohl die Anforderungen zu Beginn des Projekts als auch die Entwurfsdokumente und schließlich den Quellcode der implementierten Software. Qualitätsmerkmale für die formulierten Anforderungen wurden im Abschnitt oben bereits beschrieben.

Jedes Team eines Softwareprojekts hat das Ziel eine fehlerfreie Software zu erstellen. Bei diesem Kriterium handelt es sich um einen Qualitätsaspekt der Software. Neben diesem wichtigen Aspekt, gibt es weitere Merkmale, die die Qualität der Software beschreiben und typischerweise in Form von Anforderungen formuliert werden. Einige sind hier aufgeführt:
Bei Testverfahren kann allgemein in dynamische und statische Testverfahren unterschieden werden. Die dynamischen Testverfahren sind dadurch gekennzeichnet, dass der Prüfling (das zu prüfende Software-Produkt) mit einer konkreten Eingabe ausgeführt und in einer realen Umgebung getestet wird. Im Gegensatz dazu gibt es statische Testverfahren, bei denen der Prüfling nicht ausgeführt wird, sondern der Quellcode zu analysieren ist. Beispielsweise ist für die Eigenschaft "Änderbarkeit" keine Ausführung der Software notwendig, wohingegen für die Überprüfung der "Funktionalität" nur mit einem dynamischen Testverfahren überprüfbar ist. Beide Verfahren ergänzen sich gegenseitig.
Das dynamische Testverfahren wird dadurch gekennzeichnet, dass die zu prüfende Software mit einer konkreten Eingabe in einer realen Umgebung ausgeführt wird. Hierbei handelt es sich um ein Stichprobentest, was heißt, dass die Software stichprobenartig mit möglichen Eingaben ausgeführt wird, um Fehler zu finden. Werden keine Fehler gefunden, so impliziert dies nicht, dass es keine Fehler gibt. Demnach kann mit diesem Verfahren die Korrektheit des Prüflings nicht nachgewiesen werden. Das muss jedem beim Testen bewusst sein.
Automatische Tests (auch Unit-Tests genannt) sind im Prinzip kleine Programme, die ein Modul oder eine Komponente der Software testen. Sie werden von dem Tester einmalig programmiert und können danach jederzeit erneut ausgeführt werden, um beispielsweise nach einer Änderung des Prüflings zu schauen, ob sich Fehler eingeschlichen haben. Für die meisten Programmiersprachen existieren dazu Frameworks, die das Schreiben von automatischen Tests stark vereinfachen. Ein Testfall ist im einfachsten Fall wie folgt aufgebaut:
Etwas komplizierter wird es, wenn nicht nur eine einzelne Methode getestet werden soll sondern vielmehr das Systemverhalten beim Aufruf einer ganzen Kette von Methoden. Dann reicht es nicht mehr nur die Rückgabewerte der Methoden zu überprüfen (sofern diese überhaupt existieren) sondern es muss der resultierende Systemzustand evaluiert werden. Dieser ist oft nicht ganz so einfach zu ermitteln und hier kommt der oben erwähnte Qualitäts-Begriff der Testbarkeit ins Spiel. Bereits im Entwurf der Software sollte berücksichtigt werden, dass später geschriebene Testfälle an bestimmte Informationen leicht heran kommen müssen, um das Resultat der getesteten Aktion evaluieren zu können. Oft ist es so, dass dies immer irgendwie mit entsprechendem Aufwand möglich ist. Dem Tester kann jedoch sehr viel Arbeit abgenommen werden, wenn das von vorne herein berücksichtigt wird.
Wie kommt nun zu sinnvollen Testfällen? Einerseits sollen alle Fehler gefunden werden, andererseits können nicht alle möglichen Eingaben ausprobiert werden. In der Literatur findet man häufig Begriffe wie Äquivalenzklassenbildung[19] und Grenzwertanalyse[20]. Dahinter verbergen sich Vorgehensweisen zur systematischen Bildung von Testfällen, die möglichst viel Abdecken sollen. Bei der Wahl der Testfälle können folgende Dinge helfen:
Abschließend sei gesagt, dass der Tester eines Moduls nach Möglichkeiten nicht gleichzeitig der Author sein sollte. Für die Auswahl der Testfälle ist es besser nicht die Internen Strukturen des Modul zu kennen, sondern ausschließlich die Spezifikation.
Unittest-Frameworks gibt es für die meisten Sprachen:
Beim Erstellen von Testfällen kann es hilfreich sein zu wissen, welche Teile des Quellcodes tatsächlich abgedeckt sind und welche nicht. Struktur-Tests in Form von Quellcode-Überdeckungs-Tests können diese Frage beantworten. Dabei wird der Quellcode zunächst instrumentiert und die Testfälle dann ausgeführt. Bei der Ausführung kann das Test-Framework feststellen, welche Teile des Quellcodes ausgeführt wurden und welche nicht. Daraus können verschiedene Metriken berechnet werden, die jeweils ein unterschiedliches Maß der Überdeckung beschreiben. Eine Befehls-Überdeckung von 100% würde beispielsweise bedeuten, dass jede Zeile Quellcode von mindestens einem Testfall ausgeführt wurde. Des Weiteren gibt es noch Zweig-Überdeckung, Schleifen-Überdeckung und schließlich auch die Pfad-Überdeckung, sowie noch einige mehr. Die zuletzt genannte ist in der Praxis jedoch irrelevant, denn eine vollständige Pfad-Überdeckung würde bedeuten, dass wirklich jeder mögliche Ausführungspfad der Software von Testfällen abgedeckt wäre.
Die Erreichung bestimmter Überdeckungsmaße kann als Anforderung für Testfälle herangezogen werden. Dabei sollte jedoch stets klar sein, was die Maße im Einzelnen aussagen. Schnell suggeriert die Erreichung einer bestimmten Überdeckungsrate eine gewisse Testvollständigkeit und läutet somit das vorzeitige Ende der Bemühungen ein. Tatsächlich sagen die Maße nichts über den Sinn und Zweck der Testfälle aus. Um diesen Trugschluss von vorne herein zu vermeiden, ist es eine gute Idee den Quellcode-Überdeckungs-Test erst dann durchzuführen, wenn man der Meinung ist, dass nun alles ausreichend getestet sei. Auf diese Weise profitiert man von diesem, indem er dem Tester noch die eine oder andere Stelle Quellcode aufweist, die von den Testfällen noch nicht erreicht wurde.
Die meisten Frameworks für Quellcode-Überdeckungs-Tests bieten eine Integration für diverse Entwicklungsumgebungen an. Für Java sind zur Zeit folgende Frameworks mit unterschiedlich ausgeprägter Feature-Auswahl verfügbar:
Es ist gute Praxis, mit einer leicht destruktiven Mentalität an das Testen heranzugehen. Ein Testlauf ist dann "erfolgreich", wenn tatsächlich Fehler dabei gefunden wurden, d.h. wenn Testfälle fehlschlagen. Fehler sind in größern Projekten mit Sicherheit vorhanden, sowohl kritische als auch weniger kritische. Wenn also die gerade geschriebenen automatischen Testfälle ohne Zwischenfall zu Ende laufen, wurden "leider" keine weiteren Fehler gefunden. Es ist wichtig, diese Mentalität bei allen Team-Mitgliedern zu forcieren. Niemand im Team sollte sich über gefundene Fehler in einem fertig geglaubten Modul ärgern, im Gegenteil: Der Fehler war schon immer da, wurde aber gerade erst aufgedeckt - herzlichen Glückwunsch! Ein Grund zur Freude, denn seine Beseitigung führt zur Steigerung der Softwarequalität.
Beim Testen von Softwaresystemen mit Datenbanken kann das Testen recht umständlich werden, wenn man bedenkt dass vor jedem Test ein bestimmter Zustand in der Datenbank angenommen werden muss und nach dem Test der Ursprungszustand wieder hergestellt sein soll. Da in vielen Test-Frameworks die Ausführungsreihenfolge der Testfälle nichtdeterministisch ist, muss die Datenbank in jedem Fall immer wieder zurückgesetzt werden. Anstatt die Datenbank nun nach jedem Testfall immer wieder manuell zurückzusetzen (z.B. mit einer Kette von Löschoperationen) empfiehlt es sich, die von den meisten Datenbanksystem zur Verfügung gestellten Transaktions-Mechanismen zu verwenden. Ein Datenbank-Test könnte dann wie folgt aufgebaut sein:
Manipulationen, die nicht mit einem Datenbank-Commit abgeschlossen sind, können in der aktuellen Session sehr wohl mit einem Select gelesen werden. Diese Tatsache kann man sich beim Testen zu Nutze machen.
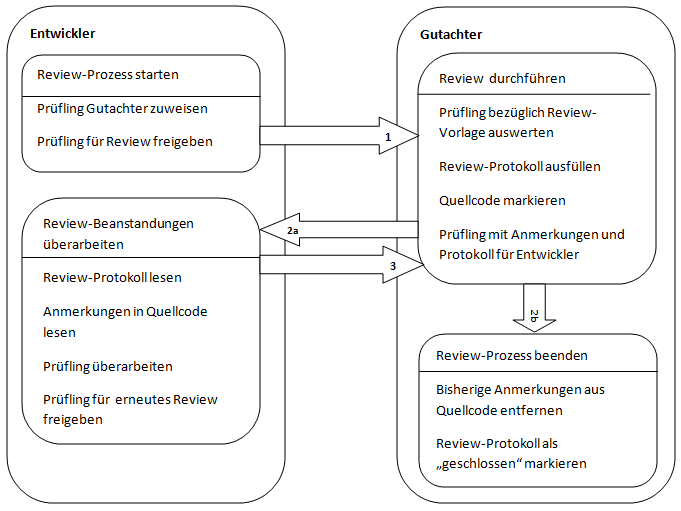
Reviews haben das schwere Los bei knapp bemessener Planung der erste Kandidat zu sein, der aufgrund von Zeitmangel gekürzt oder ganz gestrichen wird.
Wie in der Abbildung zu sehen, wird der Review Prozess für ein Prüfling (zum Beispiel eine fertig implementierte Klasse) vom Entwickler gestartet, indem er den Prüfling einem Gutachter zuordnet und für den Review-Prozess freigibt. Die Kriterien, nach denen der Gutachter anschließend den Quelltext der entsprechenden Klasse untersucht sind vorher festgelegt und werden als eine Review-Vorlage gespeichert. Falls der Gutachter Beanstandungen in der Klasse findet, werden diese im Review-Protokoll festgehalten und die zugehörigen Abschnitte im Quelltext markiert. Diese Markierungen können beispielsweise mittels Task-Tags 'REVIEW_NameDesEntwicklers' durchgeführt werden. Der Entwickler kann anschließend das Review-Protokoll sowie die Markierungen einsehen und seine Implementierung anpassen. Dies schließt er mit der Umbenennung von 'REVIEW_NameDesEntwicklers' in 'REVIEW_NameDesGutachters' ab, so dass der Gutachter über die Änderungen informiert wird. Anschließend untersucht der Gutachter die Klasse erneut. Dies wird solange durchgefügt bis der Gutachter keine Beanstandungen mehr hat. Abschließend markiert dieser das Review-Protokoll als "geschlossen" und entfernt alle zugehörigen Task-Tags aus dem Quelltext.
Vor allem bei großen Software-Projekten ist es wichtig ein Dokument mit dem Stand der Qualitätssicherung immer auf dem aktuellsten Stand zu haben. Es sollte immer direkt erkennbar sein für welche Dateien der Review-Prozess durchgeführt wurde und wie das Ergebnis des Reviews war. Nur falls ein solches Dokument existiert, kann am Ende mit Sicherheit festgestellt werden, ob für alle Dateien der Review-Prozess erfolgreich beendet wurde. Diese Dokumentation kann manuell durchgeführt werden, beispielsweise in einer Excel-Datei. Jedoch kann es passieren, dass das Dokument nicht immer auf dem aktuellsten Stand ist. Somit ist die Verwendung von Review-Tools eine empfehlenswerte Alternative. Die Vorteile eines solchen Tools sind unter anderem, dass die Reviews online durchführbar sind und somit Treffen eingespart werden können. Des Weiteren können manche Prozesse, wie beispielsweise die Zuteilung einer zu prüfenden Datei zu einem Gutachter, automatisiert werden. Darüber hinaus stellt ein solches Tool sicher, dass die Dokumentation der (Zwischen-)Ergebnisse (Protokolle) auf dem aktuellsten Stand sind und durch die automatische Aufnahme der Kommunikation zwischen dem Entwickler und Gutachter, werden alle Informationen zu den Reviews festgehalten.
Ein Beispiel für ein Review-Tool ist das webbasierte Gerrit[27], welches auf dem Versionsverwaltungssystem Git basiert.
Sie verlassen die offizielle Website der Hochschule Trier