- Hochschule Trier
- Campus wählen
- Quicklinks
-
- English
Informationsgewinnung und Wissenserwerb sind die Basis des modernen Informationszeitalters. Aufgrund der Fülle an konventionellen und elektronischen Informationsangeboten gleicht die Suche nach relevanten Informationen jedoch häufig der Suche nach der Stecknadel im Heuhaufen. Kommerzielle Internet-Suchmaschinen können das ständig wachsende Bedürfnis nach einer qualitativ hochselektiven Filterung und der Extraktion themen- und benutzerspezifischer Information nicht erfüllen. Bei den heute angewendeten Suchverfahren ist das grundsätzliche Problem die Vernachlässigung des Kontextes, in dem die Suchbegriffe stehen. So unterscheiden diese Verfahren z.B. nicht, ob mit dem Suchbegriff „Koch“ eine Berufsbezeichnung oder ein Nachname gemeint ist. Zur Verbesserung der automatischen Suche ist es daher notwendig, die bisherigen Suchverfahren so zu erweitern, dass semantische Zusammenhänge ausgewertet werden.
Im Projekt "Informationsextraktion aus dem Internet" wurden neue Verfahren entwickelt, die semantische Aspekte berücksichtigen und damit das Auffinden der benötigten Information im Internet für ein klar abgestecktes Themengebiet vereinfachen. Typische Kategorien, in welche die Suche nach gewünschten Informationen eingeteilt werden kann, sind z.B. die Recherche nach modernen Produkten, das Finden von Institutionen oder Personen oder das Ermitteln von aktuellen Forschungsergebnissen.
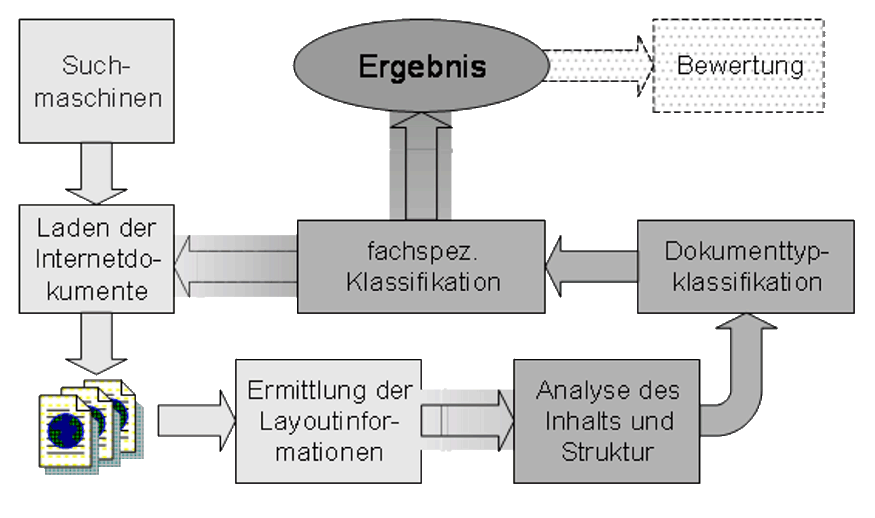
Die themenspezifische Internetsuche nutzt die Ergebnisse einer konventionellen Suchmaschine, die eine Vorauswahl von Treffern für eine spezifizierte Anfrage liefert. Die meist sehr große Treffermenge der Suchmaschinen wird dann weiter untersucht. Jeder Treffer wird nach folgendem Ablauf in mehreren Stufen analysiert: Die entsprechende Internetseite wird geladen. Text und Layoutmerkmale der Seite werden bestimmt und in ein internes Format überführt. Hieraus werden weitere Layoutmerkmale abgeleitet, d.h. es wird bestimmt, welche Begriffe besonders hervorgehoben sind. Im nächsten Schritt wird eine allgemeine Dokumenttypklassifikation durchgeführt. Diese Klassifikation ist auch eine Grundlage für die Unterscheidung von relevanten und irrelevanten Dokumenten. Allgemeine Dokumentklassen sind z.B. "private Homepage", "Institution", "Literaturverzeichnis", "Projektbericht", "Produktangebot". Auf diese erste Einteilung baut dann die fachspezifische Klassifikation und Inhaltsanalyse auf, die je nach Anwendungsgebiet angepasst werden muss. Dabei werden die Dokumente abhängig von fachlichen Kriterien in anwendungsspezifische Klassen eingeteilt. Ebenso werden bei bestimmten Dokumenttypen verschiedene Inhaltsangaben extrahiert. Der Ablauf der Analyse ist in der nachfolgenden Abbildung dargestellt.
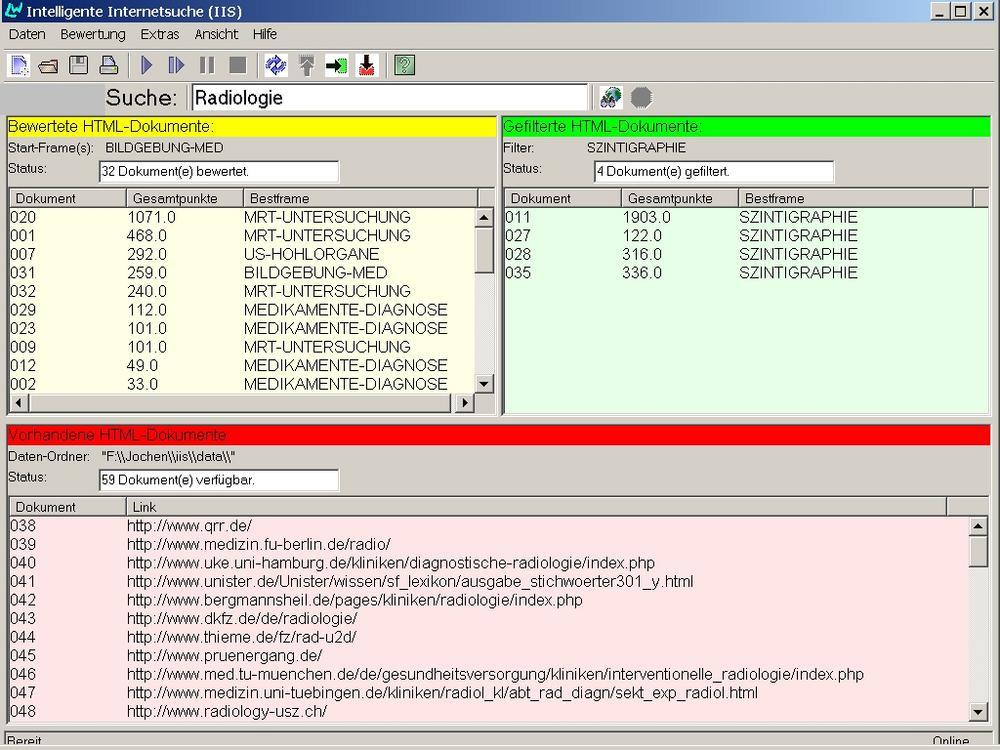
Die nachfolgende Abbildung zeigt einen Bildschirmauszug für eine Anfrage mit dem Begriff Radiologie. Nach dem Laden und der Analyse der ersten 59 Dokumente wurden 3 Seiten gefunden, die zu der vorher ausgewählten Klasse gehören.
Sie verlassen die offizielle Website der Hochschule Trier