- Hochschule Trier
- Campus wählen
- Quicklinks
-
- English
Die Masterarbeit ist im Rahmen des KEEN-Projekts (KEEN – Künstliche Intelligenz Inkubator-Labore in der Prozessindustrie, http://keen-plattform.de/) entstanden sowie in Kooperation mit der ABB AG am Forschungszentrum in Ladenburg angefertigt worden. Das Projekt zielt darauf ab, Technologien der künstlichen Intelligenz sowie Methoden des maschinellen Lernens in der Prozessindustrie einzuführen, um die Effizienz von Prozesstätigkeiten durch deren Einsatz deutlich zu steigern. Als Teil dieses Projekts befassten wir uns mit multivariaten Zeitreihendaten chemischer Batchprozesse zur Identifizierung verschiedener Herstellungsverfahren im Produktionsprozess.
Die Sensoren in den Produktionsanlagen erfassen eine große Menge an Zeitreihendaten während des Prozesses, aber die meisten dieser Daten sind nicht gelabelt. Bei den Batchprozessdaten umfassen die Labels die Bezeichnung der Prozessphase sowie den Beginn und das Ende dieser. In Anbetracht der komplexen Charakteristik multivariater Zeitreihen ist die Beschriftung oder Annotation zeitaufwändig und bedarf intensiver manueller Arbeit. Insbesondere für chemische Prozessdaten sind entsprechende Fachkenntnisse erforderlich, womit es nur von menschlichen Experten wie Chemieingenieuren durchgeführt werden kann. Infolgedessen ist es unwahrscheinlich, dass eine große Menge an gelabelten Zeitreihendaten zum Training von Methoden des vollständig überwachten maschinellen Lernens zur Verfügung steht.
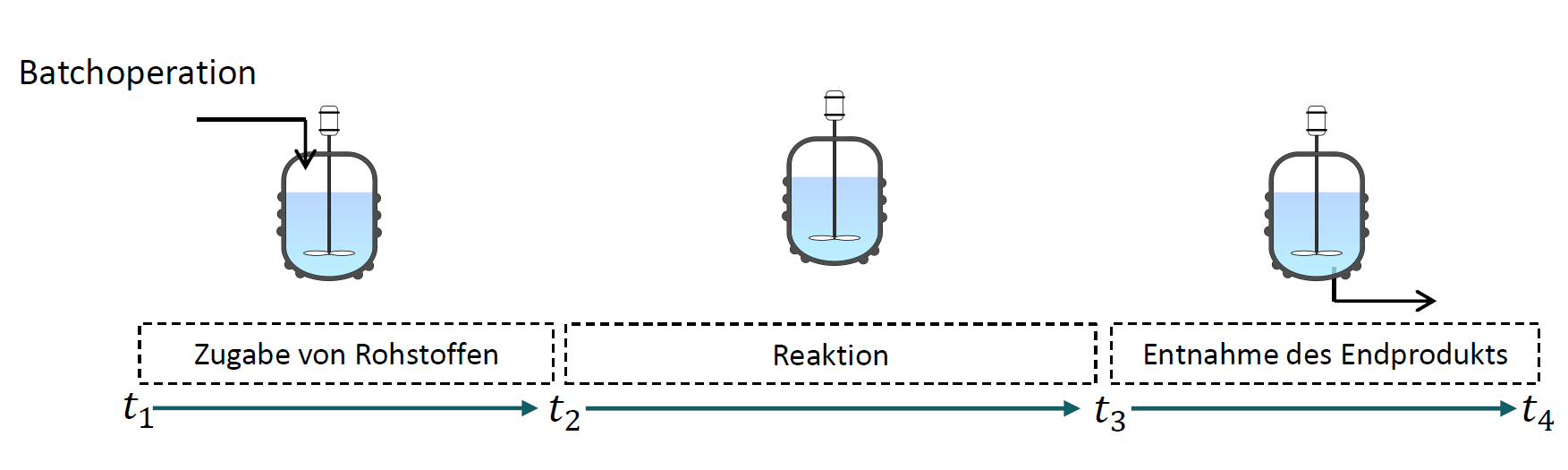
Infolgedessen werden in dieser Arbeit unüberwachte Lernmethoden zur Untersuchung und Analyse von rohen multivariaten Zeitreihen vorgestellt, mit denen die Anforderung gelabelter Zeitreihen für die Identifizierung und Segmentierung verschiedener Fertigungsverfahren in industriellen Batchprozessdaten überwunden werden kann.
Die Identifizierung und Segmentierung hat einen großen anwendungsorientierten Nutzen, da Batchprozesse weit verbreitet in der chemischen und pharmazeutischen Industrie sind und viel Bedarf an Analyse besteht. Beispielhafte Vorteile wären eine bessere Prozessüberwachung sowie Optimierung der Prozesse. Auftretende Probleme und Abweichungen könnten in einem frühen Stadium erkannt werden und Korrekturmaßnahmen während des Prozesses ergriffen werden. Auch eine Vorhersage von Ausfällen für die vorausschauende Wartung ist eine möglich Anwendung zur Verbesserung der Produktqualität und Produkterträge.

Zur Identifizierung und Segmentierung wurde ein Multilevel-Clusteringalgorithmus zur automatischen Erkennung wiederkehrender Muster und Merkmale in den Daten implementiert. Zuvor werden die rohen Zeitreihen zunächst normalisiert und mithilfe des Sliding Window-Verfahrens in kleinere Teilabschnitte unterteilt. Diese Vorverarbeitung in kleinere Segmente ist notwendig, um eine einfache Art der Vorsegmentierung zu erreichen und ein Clustering durchführen zu können. Die Methode führt zu einer hohen Anzahl an Segmenten. Daher wird im nächsten Schritt darauf abgezielt, die Dimensionalität der multivariaten Zeitfenster zu reduzieren und eine komprimierte Darstellung der Merkmale zu erlernen. Zur Dimensionsreduktion der Fenster wurde ein Long Short Term Memory Autoencoder trainiert. Die dimensionsreduzierten Features werden in Kombination mit K-Means und dem euklidischen Abstand auf dem ersten Level des Multilevel-Clusteringalgorithmus verwendet. Für jedes Cluster der ersten Ebene wird anschließend ein zweiter K-Medoids Clustering auf den Originalfenstern in Kombination mit DTW als Abstandsmetrik durchgeführt. Auf diese Weise sind ähnliche Cluster von Zeitfenstern erhalten worden, mit denen repräsentative Muster bzw. Segmente für jede Clustergruppe berechnet wurden.
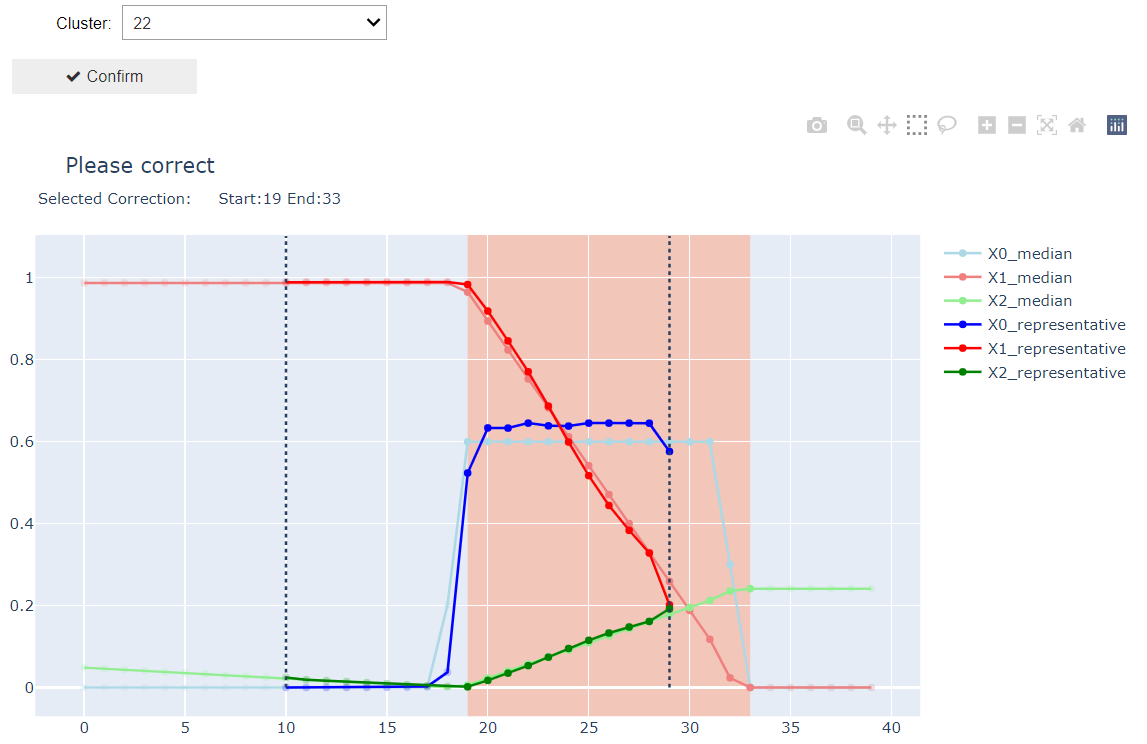
Im Anschluss wird eine Segmentierung der Zeitreihen auf Grundlage der erhaltenen Muster durchgeführt. In Anbetracht der Komplexität von Zeitreihen-Prozessdaten und dem fehlenden Vorwissen entsprechen die Muster selten genau den gesuchten Verfahren oder Phasen. Infolgedessen ist eine vorherige Korrektur dieser Muster erforderlich, um Phasen und Bereiche, die für den Nutzer von Interesse sind, genau zu erfassen. Zu diesem Zweck ist eine selbst entwickelte grafische Benutzeroberfläche realisiert worden. Mittels dieser wird dem Nutzer ermöglicht, die relevanten Bereiche interaktiv anzupassen sowie sein Fachwissen auf einfache Art und Weise einzubringen.
Durch Evaluierung der Ergebnisse konnte bewiesen werden, dass die Segmentierung und Identifizierung der Phasen oder Herstellungsverfahren basierend auf den extrahierten Muster und geringer menschlicher Interaktion erfolgreich war.

| Studierender | Nick Just | ||
| Semester | Sommersemester 2022 | ||
| Studiengang | Elektrotechnik (M.Sc.) | ||
| Art der Arbeit | Abschlussarbeit Master |
Sie verlassen die offizielle Website der Hochschule Trier
Schneidershof
Gebäude A - C | Maschinenhalle M
D-54293 Trier