- Hochschule Trier
- Campus wählen
- Quicklinks
-
- English
Diese Arbeit befasst sich mit der Schätzung der charakteristischen beschreibenden Parameter von univariaten (eindimensionalen), stochastischen Verteilungen. Die Schätzungen werden durch Python-Programme realisiert. Dabei werden zunächst analytische wie auch numerische Methoden aus der induktiven Statistik benutzt, um die entsprechenden Parameter zu schätzen. Danach folgen Schätzungen mit verschiedenen Machine-Learning Algorithmen, die mit der Python-Bibliothek scikit-learn realisiert werden.
Die Vorgehensweisen aus der induktiven Statistik sowie aus dem Bereich des Machine-Learning werden im letzten Schritt miteinander verglichen. Die Aufgabe besteht darin festzustellen, welcher der Ansätze für bestimmte Gegebenheiten, z. B. in Bezug auf die vorhandenen Daten besser oder schlechter geeignet ist.
Es wurde auf die Maximum-Likelihood Methode als analytische Methode und auf die Kleinste-Quadrate Methode als numerische Methode aus dem Bereich der induktiven Statistik zurückgegriffen. Die Machine-Learning Methoden umfassen den K-Nearest-Neighbors-, Decision-Tree-, Random-Forest-, Support-Vector-Machines- und Multi-Layer-Perceptron-Algorithmus. Die Machine-Learning Algorithmen werden in den Regressions-Varianten gewählt, damit numerische Vorhersagen gemacht werden können.
")
Die Schätzungen werden für 2 stetige Verteilungen (Normalverteilung, Exponentialverteilung) und 2 diskrete Verteilungen (Binomialverteilung und Poissonverteilung) vorgenommen. Dabei werden unterschiedlich große Stichproben der Verteilungen gezogen und deren Parameter bestimmt. Die Stichproben werden als Zufallsstichproben mit Zurücklegen angelegt, wobei die Ziehungen aus der Grundgesamtheit der Verteilungen als unabhängig voneinander betrachtet werden können. Für die Generierung der stochastischen Verteilungen wird das Modul numpy.random.Generator verwendet. Die verwendeten Stichproben können generell als unabhängig, identisch verteilte Zufallsvariablen aufgefasst werden.
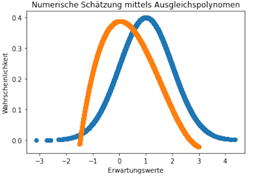
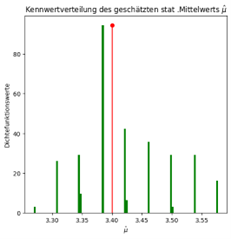
Die Schätzergebnisse werden in einem Histogramm aufgetragen und daraus eine Wahrscheinlichkeitsdichtefunktion gebildet. Dafür werden z.B. 100 Schätzungen vorgenommen. Für die Schätzung der Normalverteilung hätte man zwei Histogramme, wobei ein Histogramm die Schätzungen des Erwartungswerts µ und das andere Histogramm die Schätzungen der Varianz σ2 repräsentiert.
Anhand der aus den Histogrammen erzeugten Wahrscheinlichkeitsdichten, werden Gütekriterien wie der Erwartungswert, der mittlere quadratische Fehler und die Verzerrung (Bias) herangezogen, um die Schätzmethoden bzw. Schätzer bewerten zu können. Daraus kann man Eigenschaften der Schätzfunktionen wie z.B. die Erwartungstreue ableiten, was bedeutet, dass der Schätzer im statistischen Mittel den wahren, gesuchten Parameterwert vorhersagt.
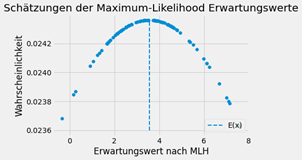
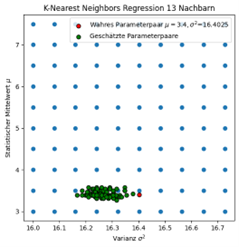
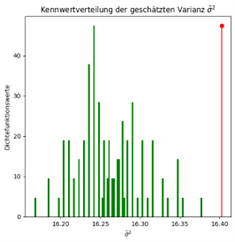
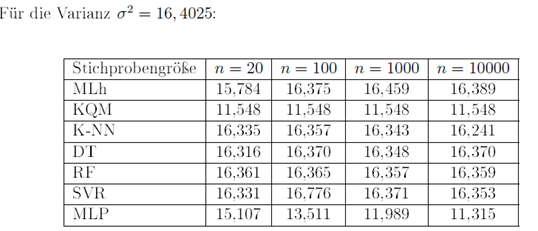
Nachdem die Schätzungen sowohl mit Methoden aus der induktiven Statistik und den Machine-Learning Algorithmen durchgeführt wurden, werden die Ergebnisse in einer Tabelle zusammengefasst und gegenübergestellt. Es wurde dabei der Erwartungswert der Schätzungen, also der Wert, den die jeweilige Schätzmethode im Mittel aus z.B. 100 Schätzungen liefert, für den Vergleich herangezogen. Der Vergleich wurde für unterschiedliche Stichprobengrößen durchgeführt.



| Studierende | Leon Falk Matthias Kroeber | ||
| Semester | Sommersemester 2022 | ||
| Studiengang | Elektrotechnik (M.Sc.) | ||
| Art der Arbeit | Teamprojekt im Master |

Sie verlassen die offizielle Website der Hochschule Trier
Schneidershof
Gebäude A - C | Maschinenhalle M
D-54293 Trier